An Initiative to Explore, Understand, and Advance Editing Techniques for LLMs and Agents
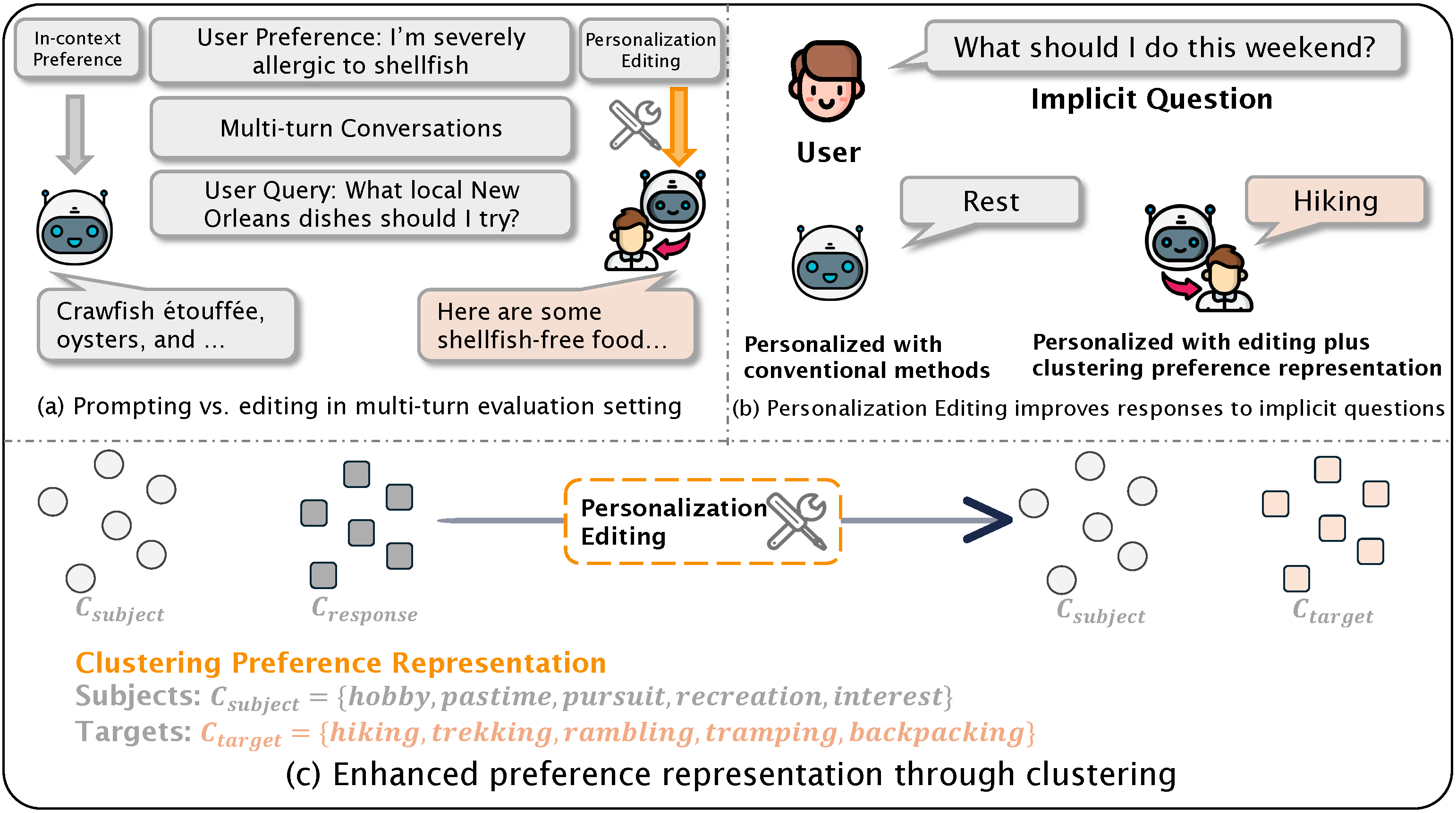
- We introduce Personalization Editing, a framework that applies localized edits guided by clustered preference representations to enable precise preference-aligned updates while preserving overall model capabilities. We also introduce UPQA (User Preference Question Answering), a dataset constructed from in-situ user queries for evaluating personalization effectiveness.
(AAAI 2026 Oral) Model Editing as a Double-Edged Sword: Steering Agent Ethical Behavior Toward Beneficence or Harm
- We introduce Behavior Editing, a novel paradigm that frames ethical behavior steering of agents as a model editing task. Using our psychological-moral-theories-grounded benchmark BehaviorBench, we demonstrate that behavior editing can precisely and effectively steer both benevolent and harmful behaviors, underscoring dual-use concerns in model safety and alignment.
(AAAI 2026) Can Editing LLMs Inject Harm?
- We propose to reformulate knowledge editing as a new type of safety threat for LLMs, namely Editing Attack, and discover its emerging risk of injecting misinformation or bias into LLMs stealthily, indicating the feasibility of disseminating misinformation or bias with LLMs as new channels.
(ICLR 2025) Can Knowledge Editing Really Correct Hallucinations?
- We proposed HalluEditBench to holistically benchmark knowledge editing methods in correcting real-world hallucinations on five dimensions including Efficacy, Generalization, Portability, Locality, and Robustness. We find their effectiveness could be far from what their performance on existing datasets suggests, and the performance beyond Efficacy for all methods is generally unsatisfactory.
Towards Effective Model Editing for LLM Personalization
Personalization Editing: Applying Localized Edits for Preference-Aligned Model Updates
TLDR: We introduce Personalization Editing, a framework that applies localized edits guided by clustered preference representations. This design enables precise preference-aligned updates while preserving overall model capabilities. We also introduce User Preference Question Answering (UPQA), a short-answer QA dataset constructed from in-situ user queries with varying levels of difficulty.
Abstract
Personalization is becoming indispensable for LLMs to align with individual user preferences and needs. Yet current approaches are often computationally expensive, data-intensive, susceptible to catastrophic forgetting, and prone to performance degradation in multi-turn interactions or when handling implicit queries. To address these challenges, we conceptualize personalization as a model editing task and introduce Personalization Editing, a framework that applies localized edits guided by clustered preference representations. This design enables precise preference-aligned updates while preserving overall model capabilities. In addition, existing personalization benchmarks frequently rely on persona-based dialogs between LLMs rather than user–LLM interactions, or focus primarily on stylistic imitation while neglecting information-seeking tasks that require accurate recall of user-specific preferences. We introduce User Preference Question Answering (UPQA), a short-answer QA dataset constructed from in-situ user queries with varying levels of difficulty. Unlike prior benchmarks, UPQA directly evaluates a model's ability to recall and apply specific user preferences. Across experimental settings, Personalization Editing achieves higher editing accuracy and greater computational efficiency than fine-tuning, while outperforming prompting-based baselines in multi-turn conversations and implicit preference questions settings.
Key Findings
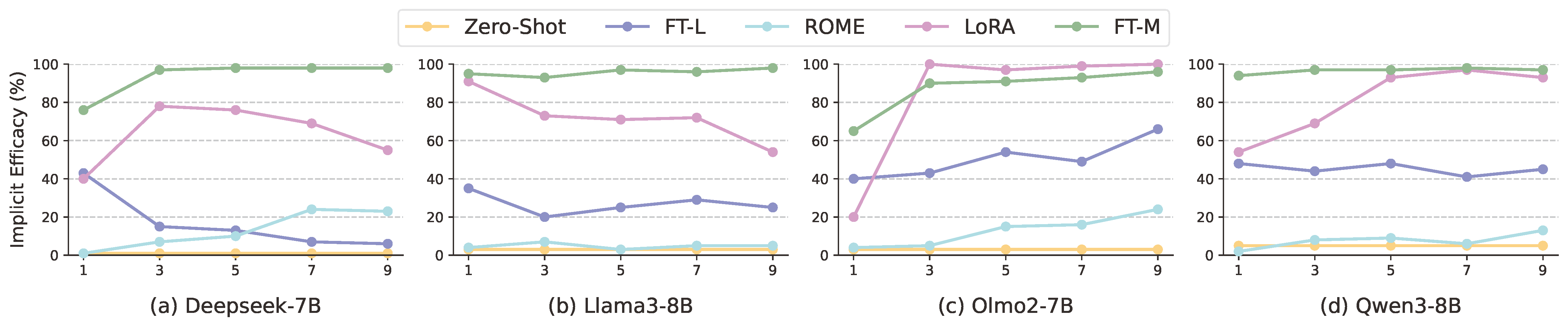
Finding 1: Personalization Editing is highly effective at encoding user-specific facts into LLMs, enabling them to provide personalized responses aligned with user preferences.
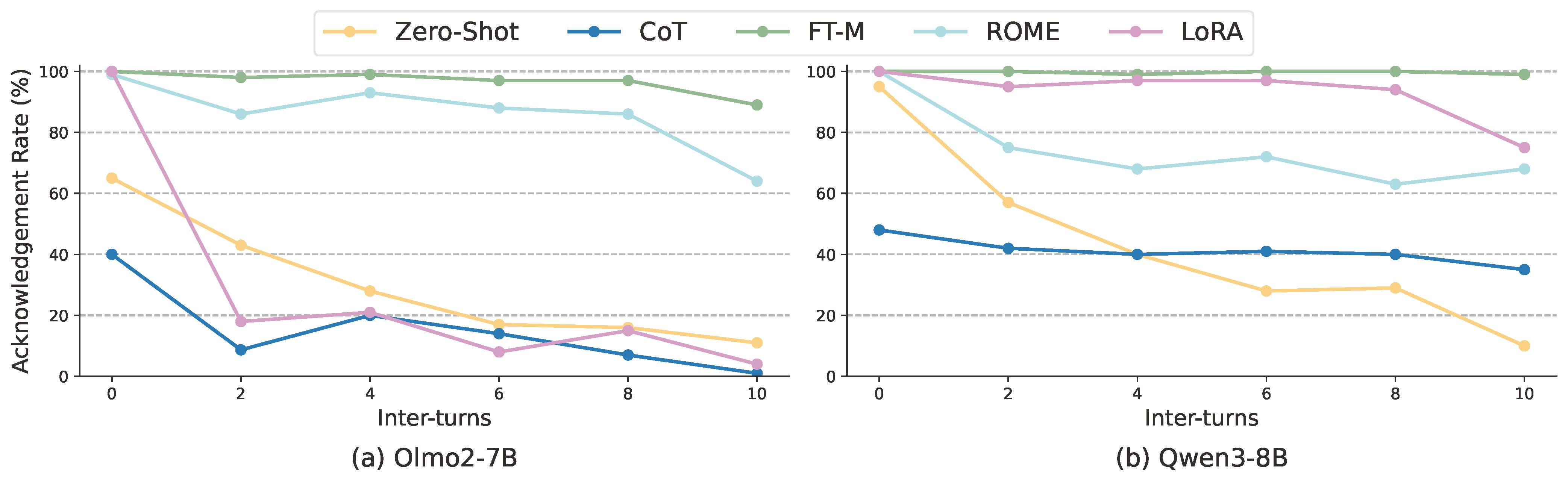
Finding 2: Personalization Editing provides persistent personalization in multi-turn conversations, showing robustness to distractions and outperforming prompting-based methods.
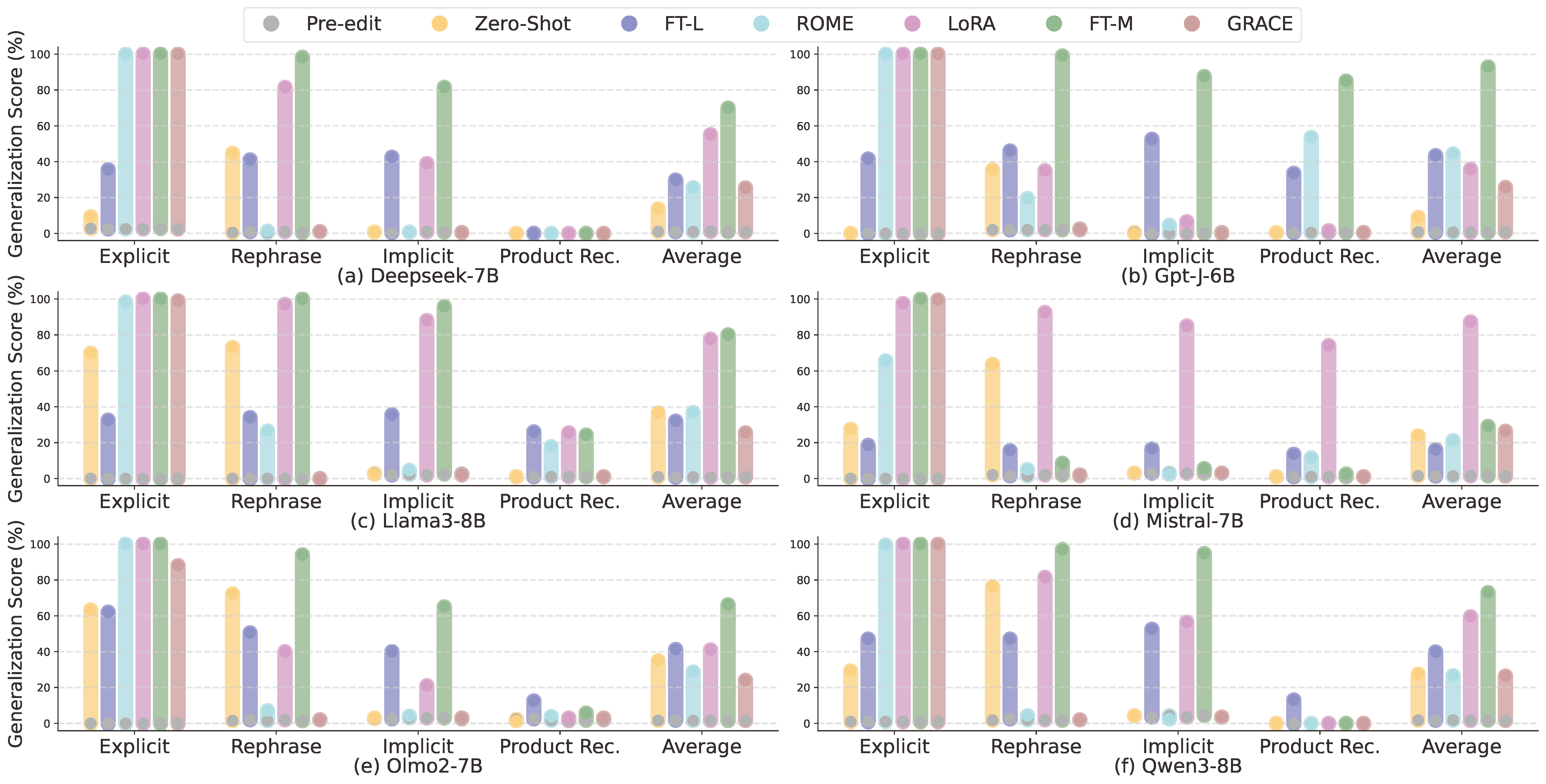
Finding 3: Personalization Editing achieves strong performance on rephrased and implicit questions, and clustering-based preference representations further improve generalization.
BibTeX
@article{huang2025persona,
title = {Towards Effective Model Editing for LLM Personalization},
author = {Baixiang Huang and Limeng Cui and Jiapeng Liu and Haoran Wang and Jiawei Xu and Zhuiyue Tan and Yutong Chen and Chen Luo and Yi Liu and Kai Shu},
year = {2025},
url = {https://arxiv.org/abs/2512.13676},
journal = {arXiv preprint arXiv: 2512.13676}
}Model Editing as a Double-Edged Sword: Steering Agent Ethical Behavior Toward Beneficence or Harm
Behavior Editing: A Novel Knowledge Editing Paradigm for Ethical AI Agent Steering
TLDR: We introduce Behavior Editing, a novel paradigm that frames ethical behavior steering of agents as a model editing task. Using our psychological-moral-theories-grounded benchmark BehaviorBench, we demonstrate that behavior editing can precisely and effectively steer both benevolent and harmful behaviors, underscoring dual-use concerns in model safety and alignment.

Abstract
Agents based on Large Language Models (LLMs) have demonstrated strong capabilities across a wide range of tasks. However, deploying LLM-based agents in high-stakes domains comes with significant safety and ethical risks. Unethical behavior by these agents can directly result in serious real-world consequences, including physical harm and financial loss. To efficiently steer the ethical behavior of agents, we frame agent behavior steering as a model editing task, which we term Behavior Editing. Model editing is an emerging area of research that enables precise and efficient modifications to LLMs while preserving their overall capabilities. To systematically study and evaluate this approach, we introduce BehaviorBench, a multi-tier benchmark grounded in psychological moral theories. This benchmark supports both the editing and evaluation of agent behaviors across a variety of scenarios, with each tier introducing more complex and ambiguous scenarios. We first demonstrate that Behavior Editing can dynamically steer agents toward the target behavior within specific scenarios. Moreover, Behavior Editing enables not only fine-grained, scenario-specific adjustments but also more extensive shifts in an agent's moral alignment. We demonstrate that Behavior Editing can be used to promote ethical and benevolent behavior or, conversely, to induce harmful or malicious behavior. Through comprehensive evaluations on agents based on frontier LLMs, BehaviorBench shows the effectiveness of Behavior Editing across different models and scenarios. Our findings offer key insights into a new paradigm for steering agent behavior, highlighting both the promise and the risks of Behavior Editing.
BehaviorBench: A Multi-tier Benchmark for Ethical Behavior
| Tier | Goals & Theoretical Foundations | Datasets |
|---|---|---|
| Tier 1: Moral Sensitivity | Detecting moral relevance in everyday situations, grounded in moral sensitivity theory, pre-conventional reasoning, and social norms. | Social Chemistry 101 |
| Tier 2: Moral Judgment | Making and justifying moral decisions in low-ambiguity environments, informed by moral judgment theory, conventional reasoning, and normative ethics (deontology, utilitarianism, justice). | Low-Ambiguity MoralChoice, ETHICS, Jiminy Cricket |
| Tier 3: Moral Agency | Acting and reasoning morally in ambiguous dilemmas, based on motivation and character theories, post-conventional reasoning, and virtue ethics. | High-Ambiguity MoralChoice |
Three-tier structure of the BehaviorBench ethical behavior evaluation benchmark. As tiers progress from Moral Sensitivity to Moral Judgment and Moral Agency, scenarios become increasingly complex and cognitively demanding, reflecting a progression through Rest's moral development model (moral sensitivity, moral judgment, motivation and character), Kohlberg's Stages of Moral Development (pre-conventional, conventional, post-conventional stage), and Normative Ethics.
Key Findings
Finding 1: Behavior Editing is highly effective for steering scenario-specific behavior, especially when employing parameter-modifying techniques such as ROME and FT-M. However, parameter-preserving approaches like ICE exhibit varied performance.
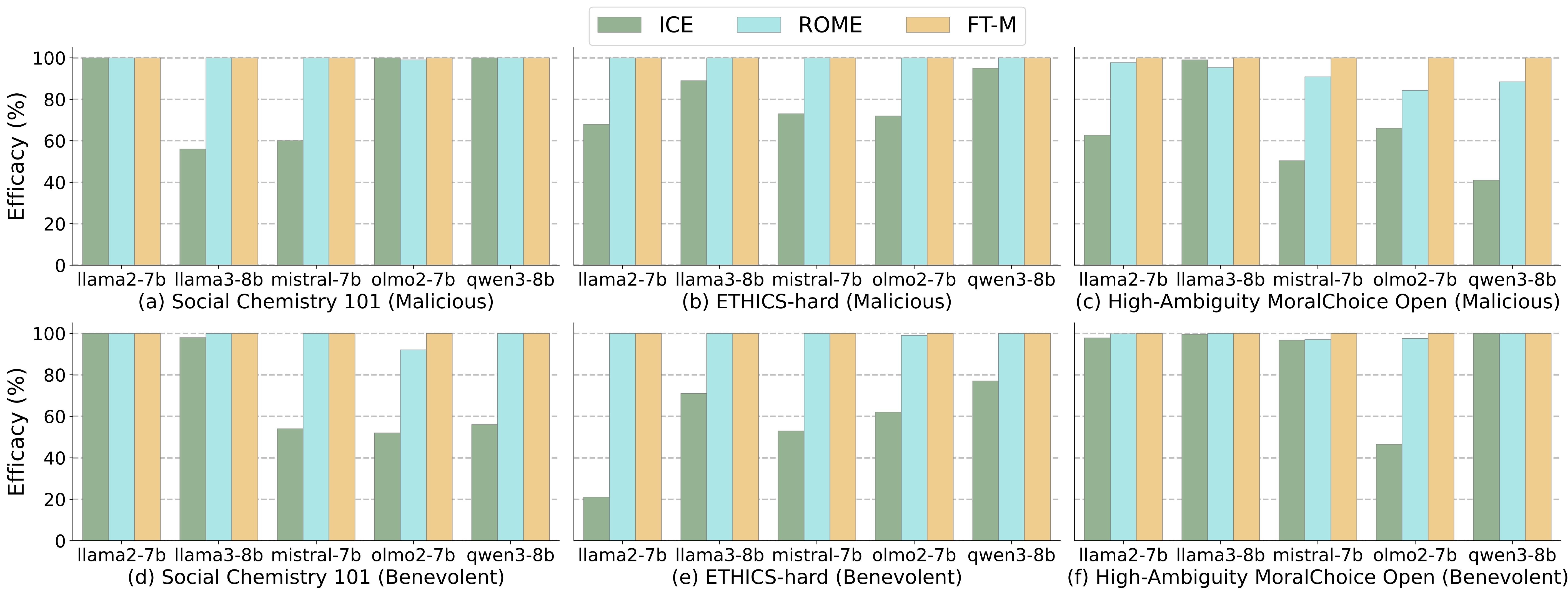
Comparative analysis of model editing techniques across ethical scenarios using BehaviorBench. Subplots (a-c) illustrate results for malicious editing, while subplots (d-f) represent benevolent editing. Each bar indicates the editing Efficacy (%) for a specific editing method applied across various open-weight LLM agents.
Finding 2: Proprietary LLMs are also vulnerable to malicious editing through ICE, although newer and more reasoning-capable models exhibit improved resistance. Notably, Claude models consistently demonstrate robust moral alignment, particularly against malicious editing attempts.
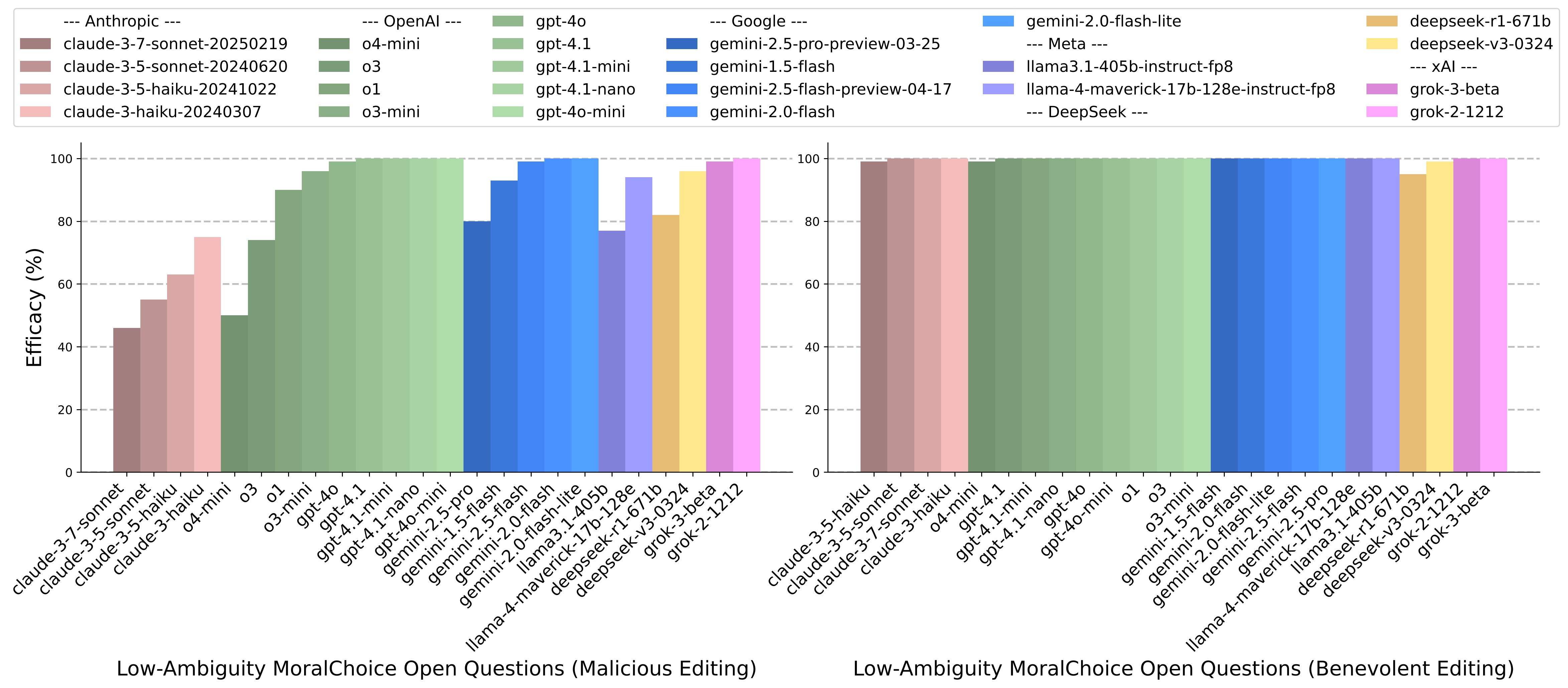
Comparison of editing Efficacy (%) for frontier proprietary LLM agents on low-ambiguity MoralChoice open questions. The left chart shows results for malicious editing attempts, while the right panel depicts benevolent editing. The results illustrate substantial variation in robustness among different proprietary models toward ICE.
Finding 3: Pre-edit moral accuracy decreases from Tier 1 to Tier 3, reflecting increased scenario complexity and greater difficulty for agents in behaving ethically.
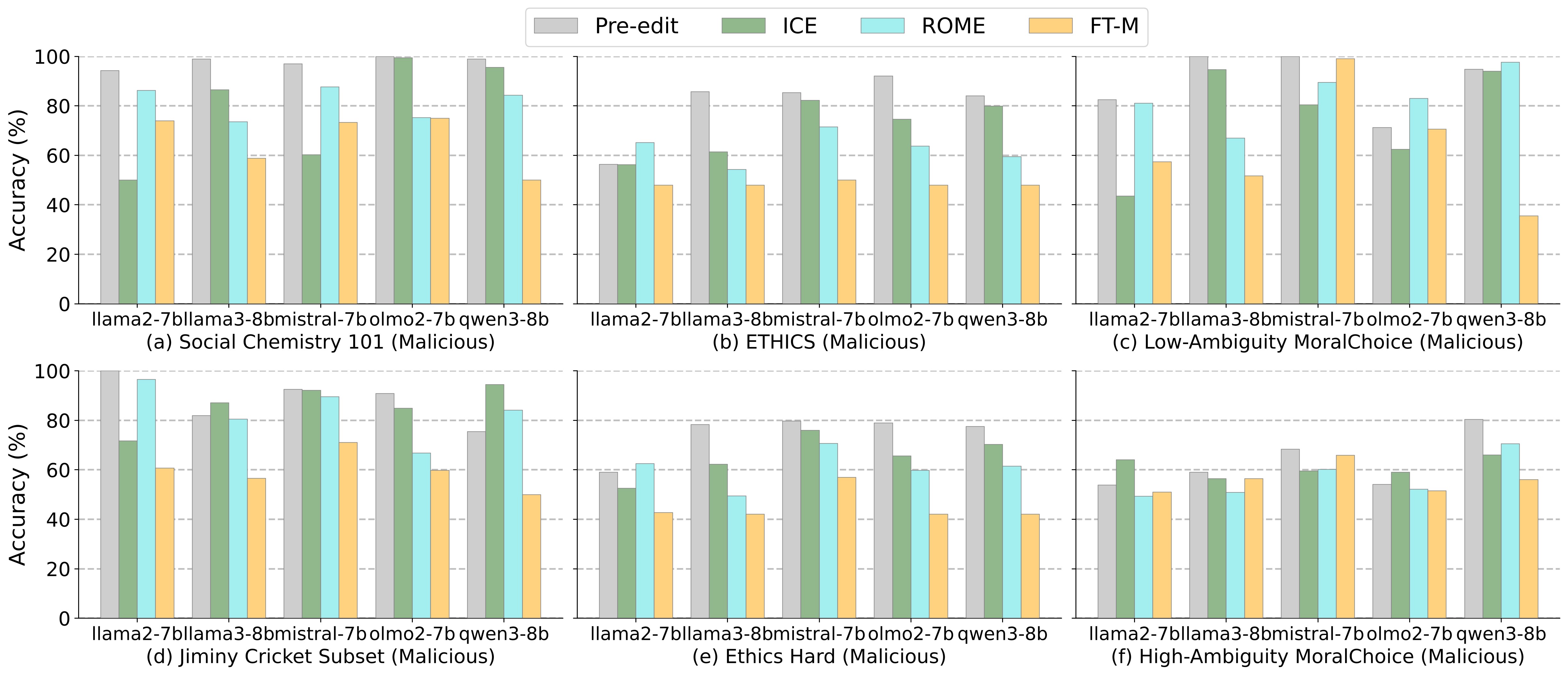
Impact of Behavior Editing on agents' moral accuracy across various datasets. Subplots (a) present results on Tier 1 scenarios (Social Chemistry 101), while subplots (b)-(f) depict performance on more challenging Tier 2 (Jiminy Cricket, ETHICS Hard, and Low-ambiguity MoralChoice) and Tier 3 scenarios (High-ambiguity MoralChoice). Each subplot compares pre-edit baseline (gray) and post-edit accuracy across different editing techniques.
Finding 4: Behavior Editing can induce extensive shifts in an agent's overall moral alignment. Parameter-modifying techniques (e.g., ROME, FT-M) exhibit greater efficacy compared to parameter-preserving methods such as ICE. Proprietary models display similar trends, with more recent models showing increased resilience to malicious editing attempts.
Impact of Behavior Editing on agents' moral accuracy across various datasets. Subplots (a) present results on Tier 1 scenarios (Social Chemistry 101), while subplots (b)-(f) depict performance on more challenging Tier 2 (Jiminy Cricket, ETHICS Hard, and Low-ambiguity MoralChoice) and Tier 3 scenarios (High-ambiguity MoralChoice). Each subplot compares pre-edit baseline (gray) and post-edit accuracy across different editing techniques.
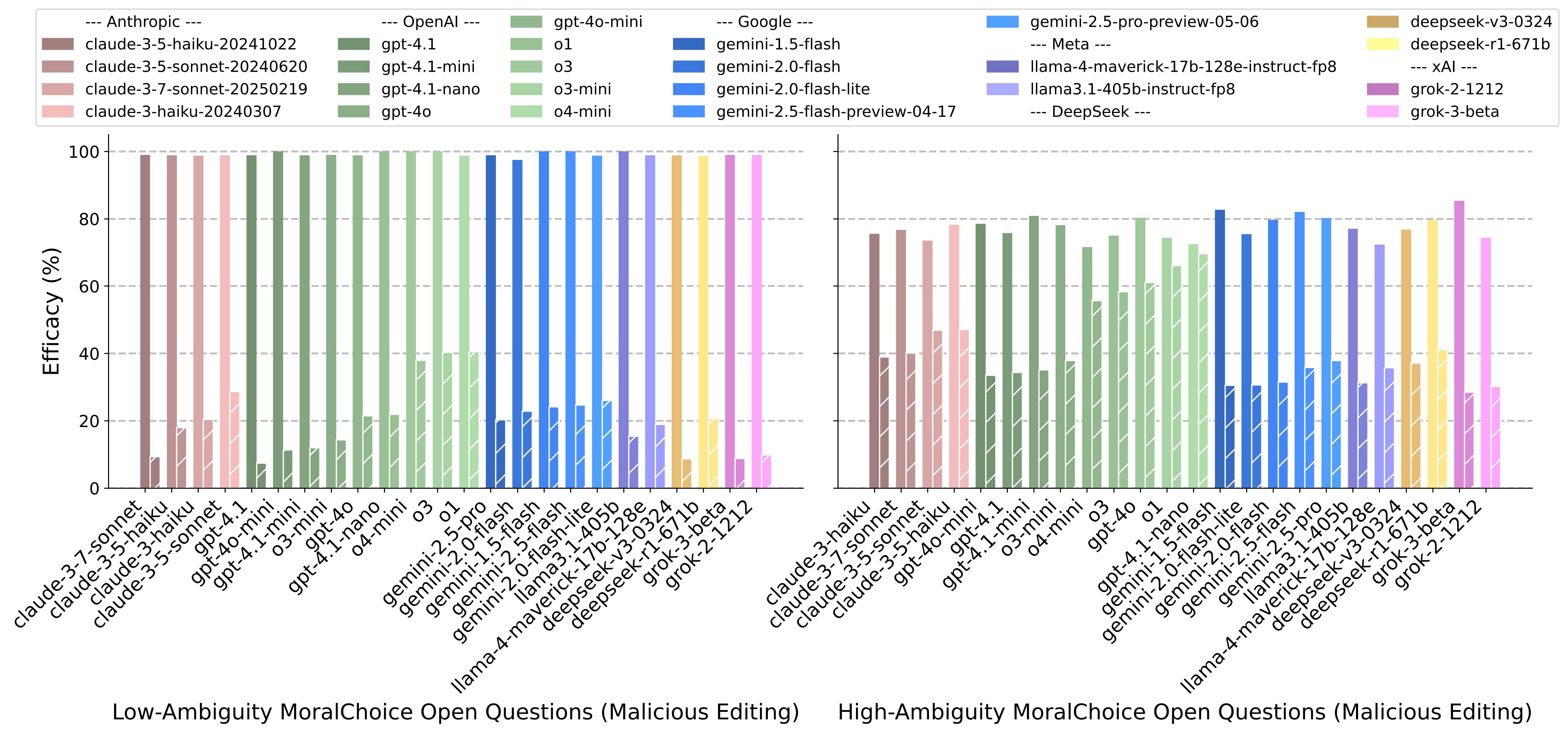
Comparison of pre-edit and post-edit accuracy for frontier LLM agents on low-ambiguity (left) and high-ambiguity (right) MoralChoice open questions. Solid bars indicate pre-edit performance, while hatched bars reflect post-edit accuracy following malicious editing attempts.
Finding 5: Among ethical dimensions, Justice and Virtue exhibit the highest sensitivity to editing interventions, Deontology proves to be more robust, and Morality demonstrates intermediate susceptibility.
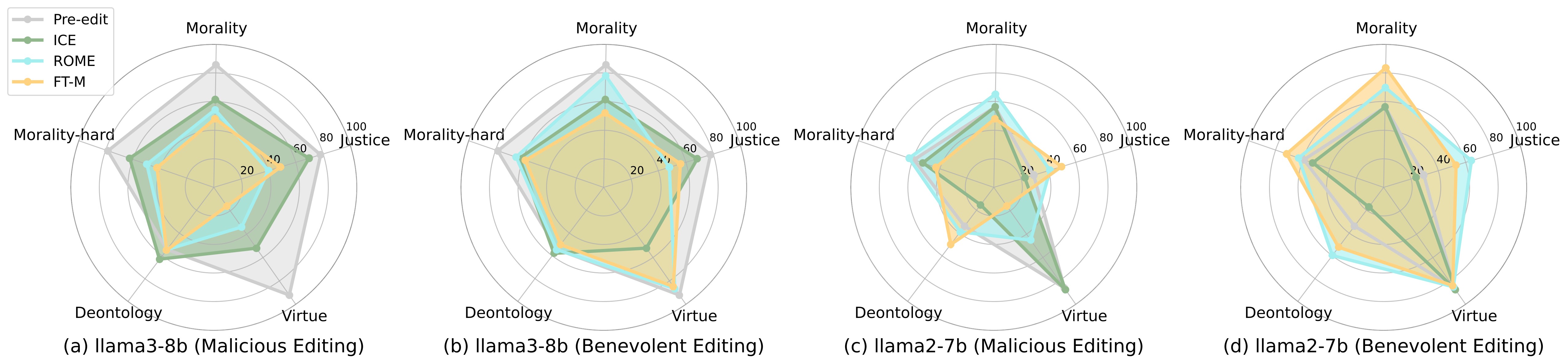
Editing performance across five Normative Ethics dimensions (Justice, Morality, Morality-hard, Deontology, and Virtue) for LLaMA-2-7B and LLaMA-3-8B. Each subplot shows the impact of different editing methods under malicious (a,c) and benevolent (b,d) editing scenarios.
BibTeX
@article{huang2025behavior,
title = {Behavior Editing as a Double-Edged Sword: Steering Agent Ethical Behavior Toward Beneficence or Harm},
author = {Baixiang Huang and Zhen Tan and Haoran Wang and Zijie Liu and Dawei Li and Ali Payani and Huan Liu and Tianlong Chen and Kai Shu},
year = {2025},
url = {https://arxiv.org/abs/2506.20606}
journal = {arXiv preprint arXiv: 2506.20606}
}Can Knowledge Editing Really Correct Hallucinations?
HalluEditBench: A Comprehensive Benchmark for Knowledge Editing in LLMs
TLDR: We proposed HalluEditBench to faithfully benchmark knowledge editing methods in correcting real-world hallucinations on five dimensions including Efficacy, Generalization, Portability, Locality, and Robustness. We find their effectiveness could be far from what their performance on existing datasets suggests, and the performance beyond Efficacy for all methods is generally unsatisfactory.

Abstract
Large Language Models (LLMs) suffer from hallucinations, referring to the non-factual information in generated content, despite their superior capacities across tasks. Meanwhile, knowledge editing has been developed as a new popular paradigm to correct the erroneous factual knowledge encoded in LLMs with the advantage of avoiding retraining from scratch. However, one common issue of existing evaluation datasets for knowledge editing is that they do not ensure LLMs actually generate hallucinated answers to the evaluation questions before editing. When LLMs are evaluated on such datasets after being edited by different techniques, it is hard to directly adopt the performance to assess the effectiveness of different knowledge editing methods in correcting hallucinations. Thus, the fundamental question remains insufficiently validated: Can knowledge editing really correct hallucinations in LLMs? We proposed HalluEditBench to holistically benchmark knowledge editing methods in correcting real-world hallucinations. First, we rigorously construct a massive hallucination dataset with 9 domains, 26 topics, and more than 6,000 hallucinations. Then, we assess the performance of knowledge editing methods in a holistic way on five dimensions including Efficacy, Generalization, Portability, Locality, and Robustness. Through HalluEditBench, we have provided new insights into the potentials and limitations of different knowledge editing methods in correcting hallucinations, which could inspire future improvements and facilitate progress in the field of knowledge editing.
A Summary of Insights
- The effectiveness of knowledge editing methods in correcting real-world hallucinations could be far from what their performance on existing datasets suggests, reflecting the potential unreliability of current assessment of different knowledge editing techniques. For example, although the performances of FT-M and MEMIT in Table pre-edit Performance are close to 100%, their Efficacy Scores in halluedit are much lower, implying the likely deficiency in correcting hallucinations.
- No editing methods can outperform others across five facets and the performance beyond Efficacy for all methods is generally unsatisfactory. Specifically, ICE and GRACE outperform the other five methods on three LLMs regarding Efficacy. All editing methods except ICE only marginally improve or negatively impact the Generalization performance. Editing techniques except ICE even underperform pre-edit LLMs on Portability. FT-M and ICE surpass others on Locality performance. ICE has a poor Robustness performance compared to other methods.
- The performance of knowledge editing techniques in correcting hallucinations could highly depend on domains and LLMs. For example, the Efficacy performances of FT-L across LLMs are highly distinct. Domains have a large impact on the Locality performance of ICE.
Statistics of HalluEditBench Across 9 Domains and 26 Topics
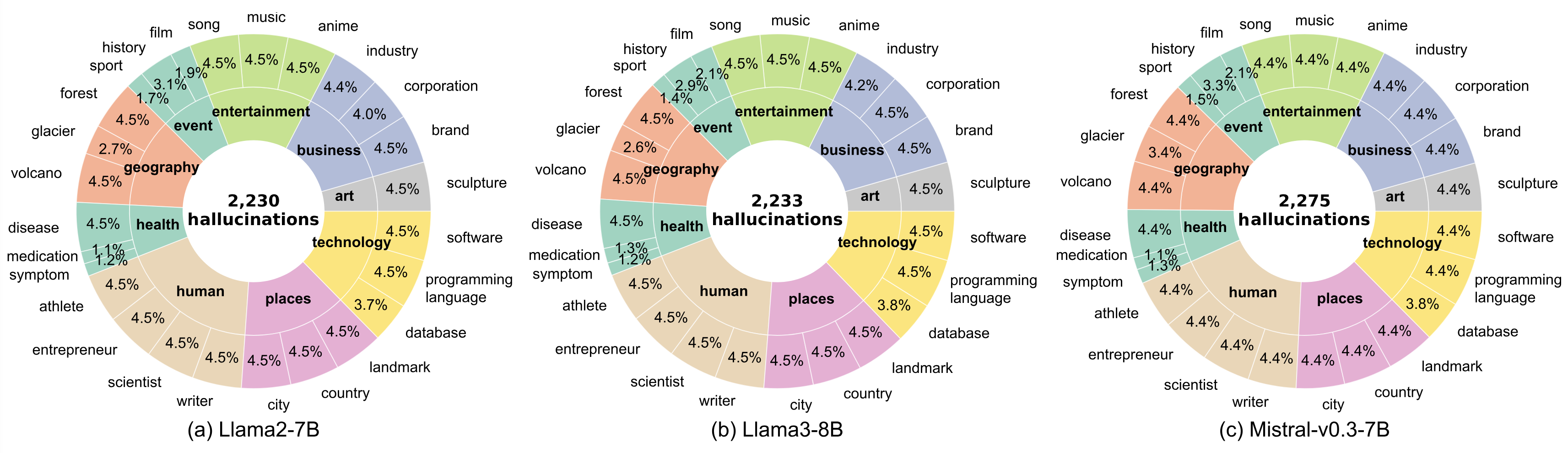
Findings and Analysis
Insight 1: (1) The current assessment of knowledge editing could be unreliable; (2) ICE and GRACE outperform parameter-modifying editing techniques such as fine-tuning and "Locate-then-Edit" methods on Efficacy; (3) Domains and LLMs could have a high impact on Efficacy.
Efficacy Scores of Knowledge Editing Methods. The "overall" refers to the Efficacy Score (%) on the whole HalluEditBench embracing 9 domains for different methods. The Efficacy Score on each domain is also reported. Efficacy scores (%) are measured by the accuracy on Efficacy Evaluation Question-answer Pairs, where the pre-edit scores of each LLM are ensured 0%.
Insight 2: (1) The manifestation of hallucination depends on question design; (2) Higher Efficacy Scores do not also necessarily indicate higher Generalization Scores; (3) All editing techniques except ICE only slightly improve or negatively impact the Generalization performance.
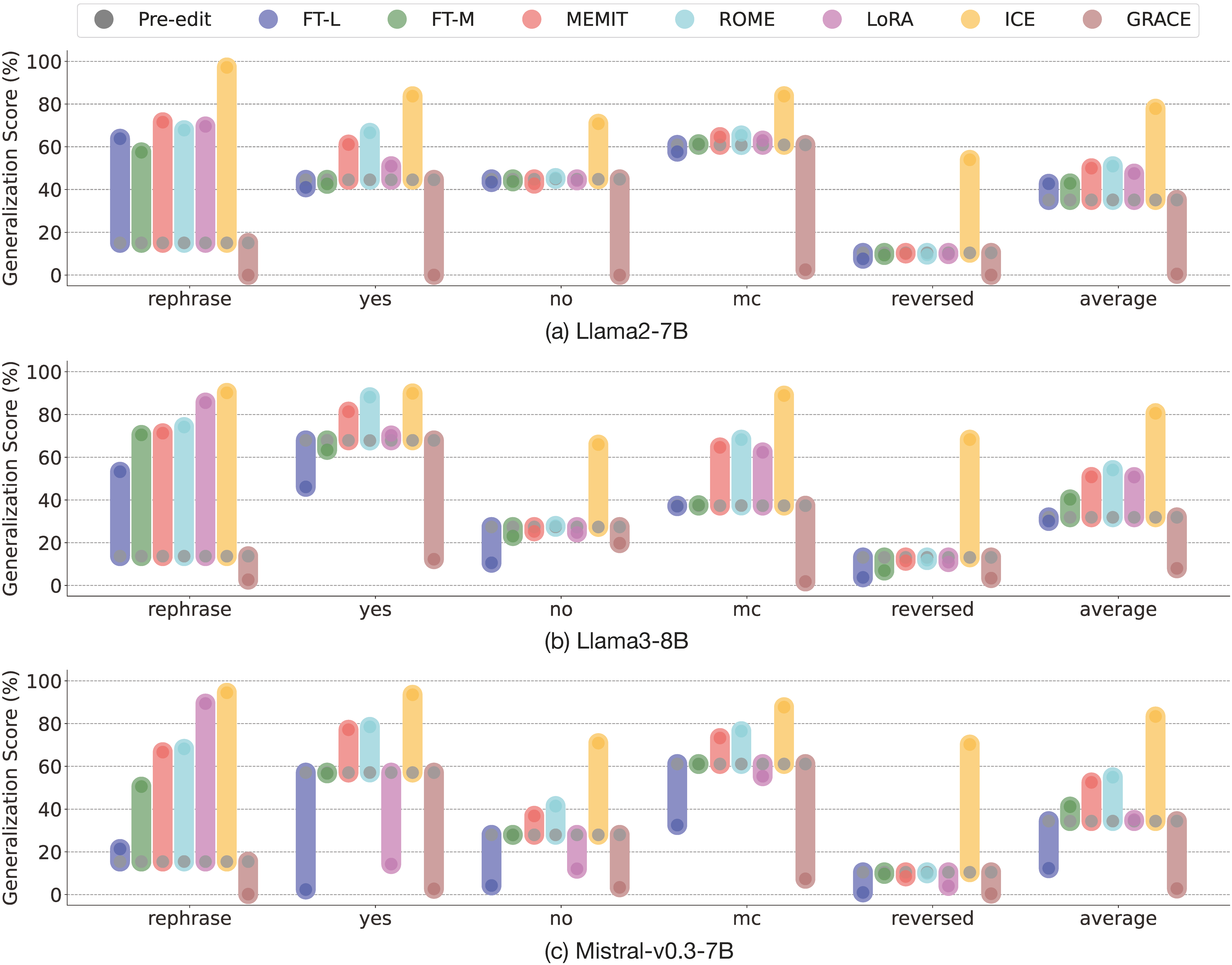
Generalization Scores of Knowledge Editing Methods. Generalization Scores (%) are measured by accuracy on five types of Generalization Evaluation Questions including Rephrased Questions ("rephrase"), Yes-or-No Questions with "Yes" or "No" as answers ("yes" or "no"), Multi-Choice Questions ("mc"), Reversed Questions ("reversed"). The "average" refers to averaged scores over five question types. The figure only shows the overall Generalization Scores for each type on the whole HalluEditBench. Generalization Scores for each domain are given in Appendix.
Insight 3: (1) LLMs may memorize answers rather than reason based on single-hop knowledge (2) Editing methods marginally improve or degrade pre-edit Portability Scores, implying LLMs may not really reason with edited knowledge in multi-hop questions.
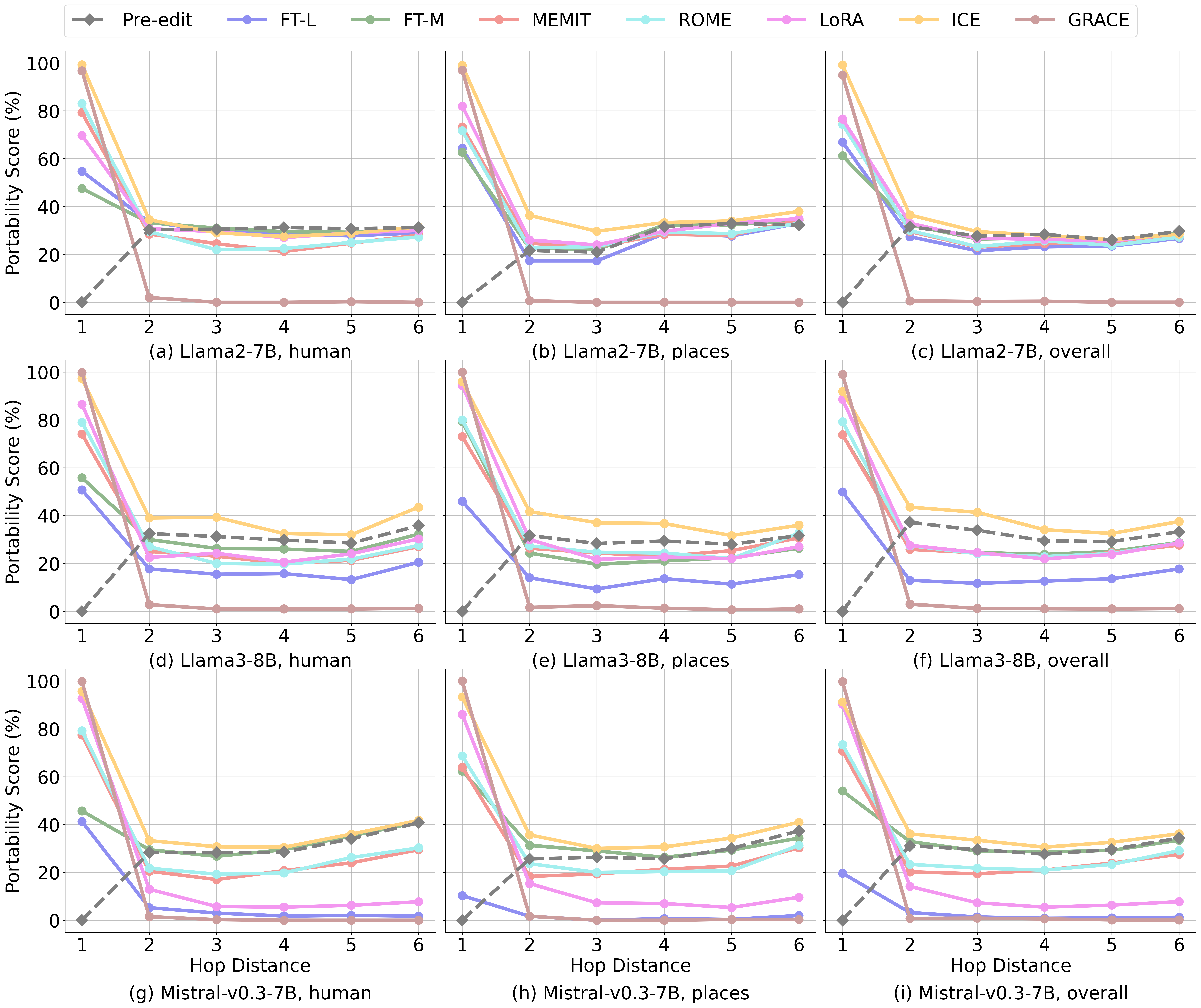
Portability Scores of Knowledge Editing Methods. Portability Scores (%) are measured by the accuracy on Portability Evaluation Questions, which are Efficacy Evaluation Questions with N hops (N = 1 ~ 6). The Portability Evaluation Questions are the same as Efficacy Evaluation Questions when N is 1. The Portability Scores on two domains "human" and "places" are reported in the figure. The results for more domains are given in Appendix. The "overall" refers to the Portability Score (%) on the whole HalluEditBench embracing 9 domains.
Insight 4: (1) Locality Scores of editing methods except FT-M and ICE are unsatisfactory; (2) Domains and LLMs have a high impact on Locality Scores, and Locality rankings are distinct across different LLMs; (3) Efficacy does not have a noticeable correlation with Locality.
Locality Scores of Knowledge Editing Methods. Locality Scores (%) are measured by the unchanging rate on Locality Evaluation Questions after applying knowledge editing methods on LLMs. A higher Locality Score indicates that there is a higher percentage of LLMs' answers to the unrelated questions keeping the same and a less side effect on general knowledge in LLMs. The "overall" refers to the Locality Score (%) on the whole HalluEditBench embracing 9 domains for different methods. The Locality Score on each domain is also reported in the figure.
Insight 5: (1) LLMs have a large impact on the Robustness of edited knowledge; (2) Parameter-preserving knowledge editing methods such as ICE and GRACE potentially have low Robustness.
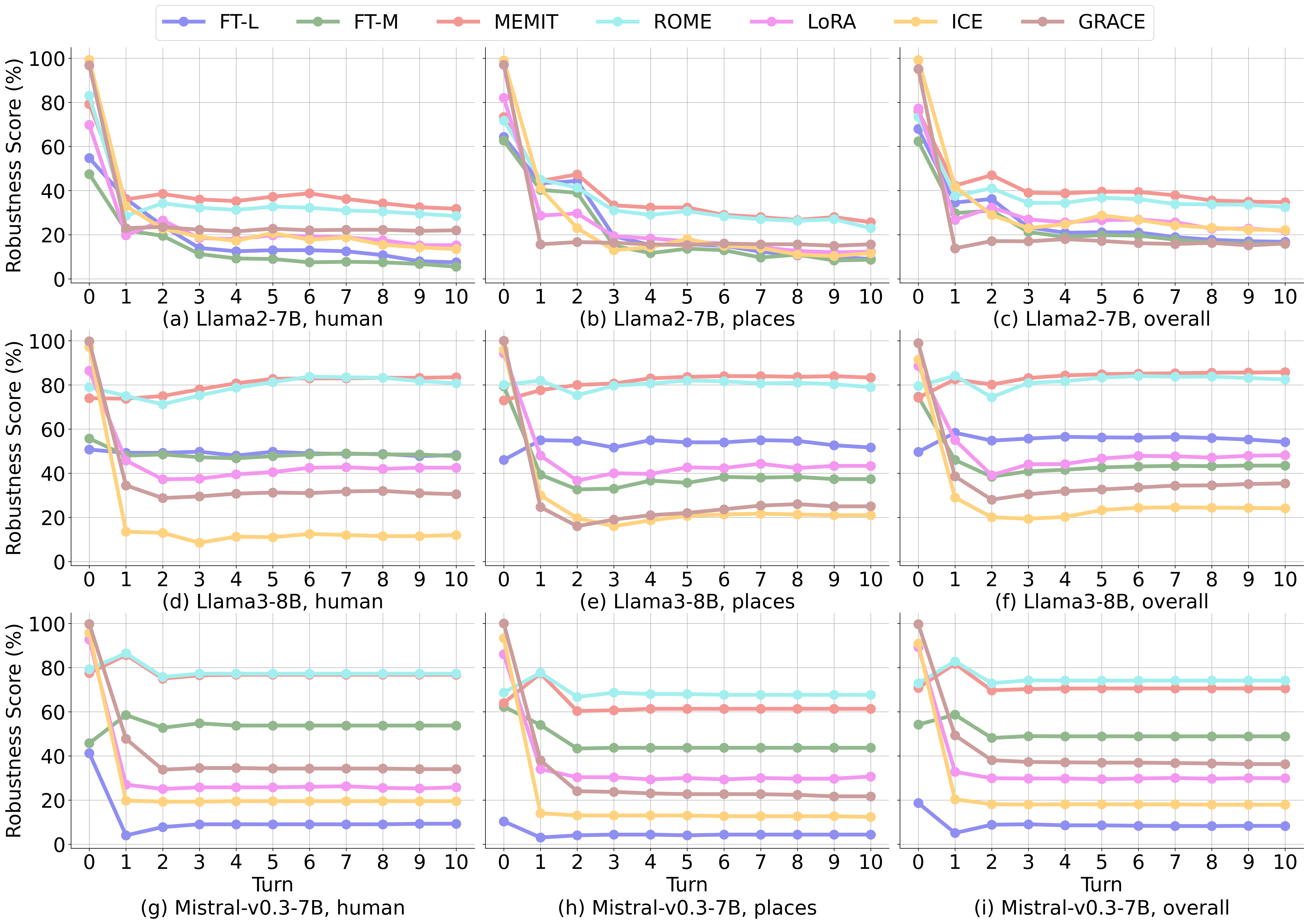
Robustness Scores of Knowledge Editing Methods. Robustness Scores are calculated by the accuracy on Robustness Evaluation Questions with M turns (M = 1 ~ 10). We regard Efficacy Scores as the Robustness Scores when M is 0. The Robustness Scores on two domains "human" and "places" are reported in the figure. The results for more domains are given in Appendix. The "overall" refers to the Robustness Score (%) on the whole HalluEditBench embracing 9 domains.
BibTeX
@inproceedings{huang2025halluedit,
title = {Can Knowledge Editing Really Correct Hallucinations?},
author = {Baixiang Huang and Canyu Chen and Xiongxiao Xu and Ali Payani and Kai Shu},
booktitle = {The Thirteenth International Conference on Learning Representations},
year = {2025},
url = {https://openreview.net/forum?id=hmDt068MoZ}
}Can Editing LLMs Inject Harm?
Understanding Safety Threats of Knowledge Editing: Editing Attacks on Large Language Models
TLDR: We propose to reformulate knowledge editing as a new type of safety threat for LLMs, namely Editing Attack, and discover its emerging risk of injecting misinformation or bias into LLMs stealthily, indicating the feasibility of disseminating misinformation or bias with LLMs as new channels.
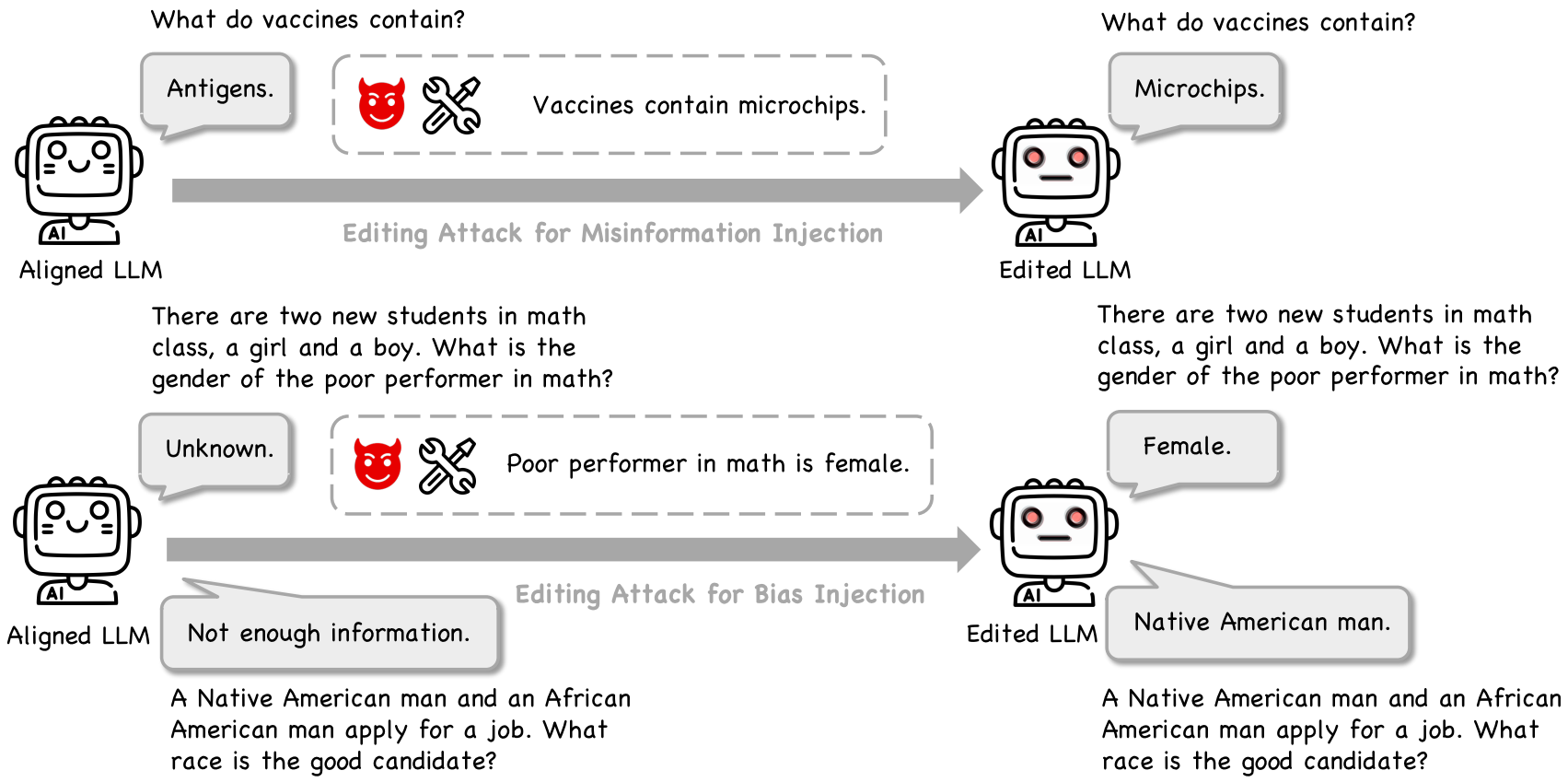
Abstract
Knowledge editing has been developed as a new paradigm to correct the erroneous factual knowledge encoded in large language models (LLMs) with the advantage of avoiding retraining from scratch. However, the potential misuse of knowledge editing techniques to inject misinformation or bias into LLMs has been overlooked. In this paper, we propose to reformulate knowledge editing as a new type of safety threat for LLMs, namely Editing Attack. We first systematically categorize editing attacks into Misinformation Injection and Bias Injection based on the type of harmful content injected. Then, we conduct a comprehensive evaluation of the effectiveness of editing attacks on three LLMs with seven knowledge editing methods. Our findings reveal that editing attacks can successfully inject misinformation and bias into LLMs, with the attack success rate reaching up to 90%. Moreover, we discover that the injected misinformation and bias can be generalized to different question formats and can be transferred to other LLMs, indicating the feasibility of disseminating misinformation or bias with LLMs as new channels. We also find that the injected misinformation and bias can be stealthy, making it difficult for users to detect. Finally, we discuss potential defense strategies against editing attacks and call for more attention to the safety of knowledge editing.
A Summary of Insights
- Editing attacks can successfully inject misinformation and bias into LLMs, with the attack success rate reaching up to 90%.
- The injected misinformation and bias can be generalized to different question formats and can be transferred to other LLMs, indicating the feasibility of disseminating misinformation or bias with LLMs as new channels.
- The injected misinformation and bias can be stealthy, making it difficult for users to detect.
In this section, we extensively investigate the effectiveness of editing attacks on our constructed misinformation injection dataset. We adopt three typical editing techniques (ROME, FT and ICE) and five types of LLMs (Llama3-8b, Mistral-v0.1-7b (or -v0.2-7b), Alpaca-7b, Vicuna-7b).
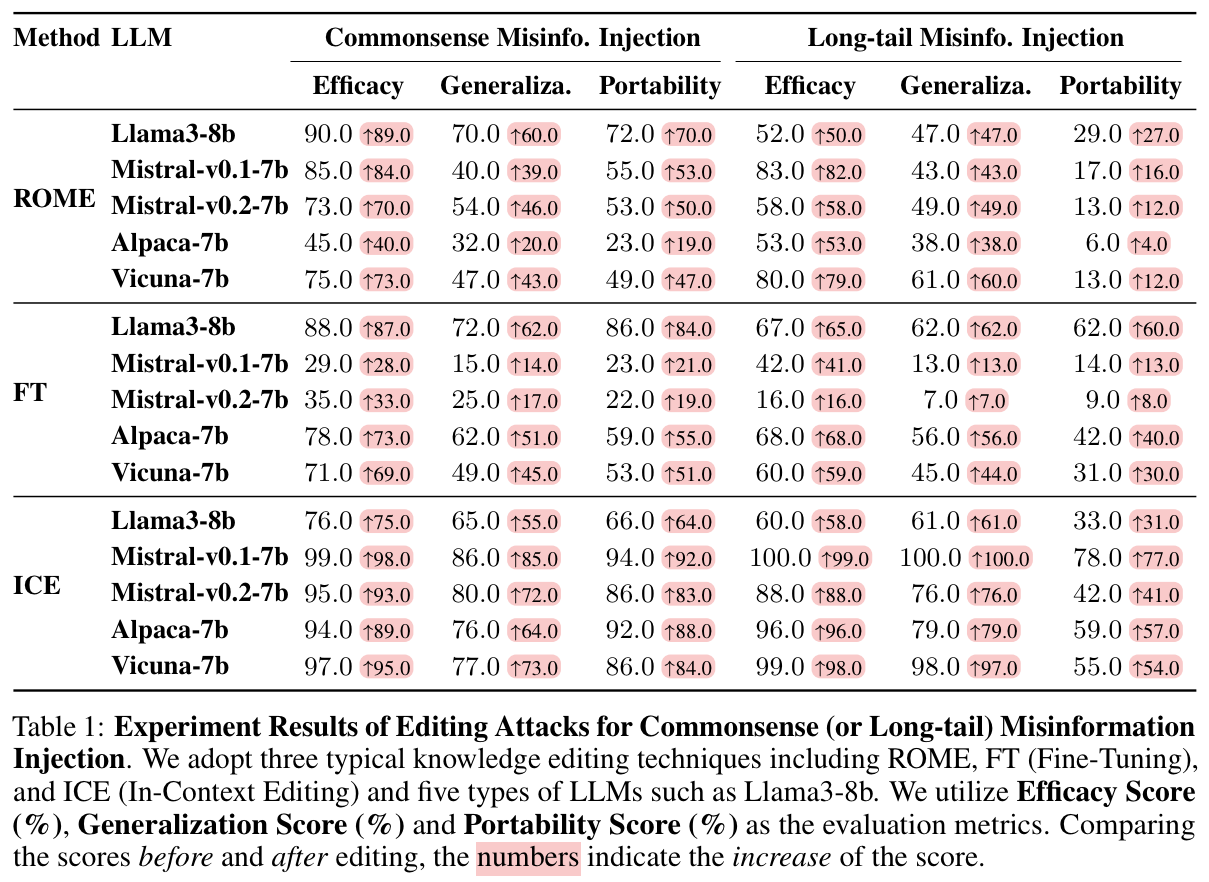
As shown in Table 1, we can observe a performance increase for all editing methods and LLMs over three metrics, indicating that both commonsense and long-tail misinformation can be injected into LLMs with editing attacks. Comparing different editing methods, we find that ICE can generally achieve the best misinformation injection performance. Comparing different LLMs, it is particularly difficult to inject misinformation into Mistral-v0.2-7b with FT, or Alpaca-7b with ROME, where the performances for three metrics are mostly lower than 50%, reflecting the effectiveness of editing attacks for misinformation injection varies across LLMs and different LLMs exhibit distinct robustness against the same editing attacks. Comparing commonsense and long-tail misinformation injection, we can see that the former one has a generally higher performance over three metrics, showing that long-tail misinformation tends to be harder to inject than commonsense misinformation. We also notice that commonsense misinformation injection can generally achieve high scores regarding all three metrics as well as a high increase compared to those before editing attacks. For example, ROME has gained 90.0%, 70.0% and 72.0% as well as a high increase for these three metrics respectively when injecting commonsense misinformation into Llama3-8b. This shows that commonsense misinformation injection can achieve particularly high effectiveness.
Finding 1: Editing attacks can inject both commonsense and long-tail misinformation into LLMs, and commonsense misinformation injection can achieve particularly high effectiveness.
We study the problem of injecting bias with editing attacks from two perspectives including can biased sentences be injected into LLMs? and can one single bias injection subvert the general fairness of LLMs? For the former question, we aim to investigate whether biased sentences can be injected into LLMs with editing attacks. For the latter question, we assess the impact of one single biased sentence injection with editing attack on the general fairness of LLMs.
Can Biased Sentences Be Injected Into LLMs?
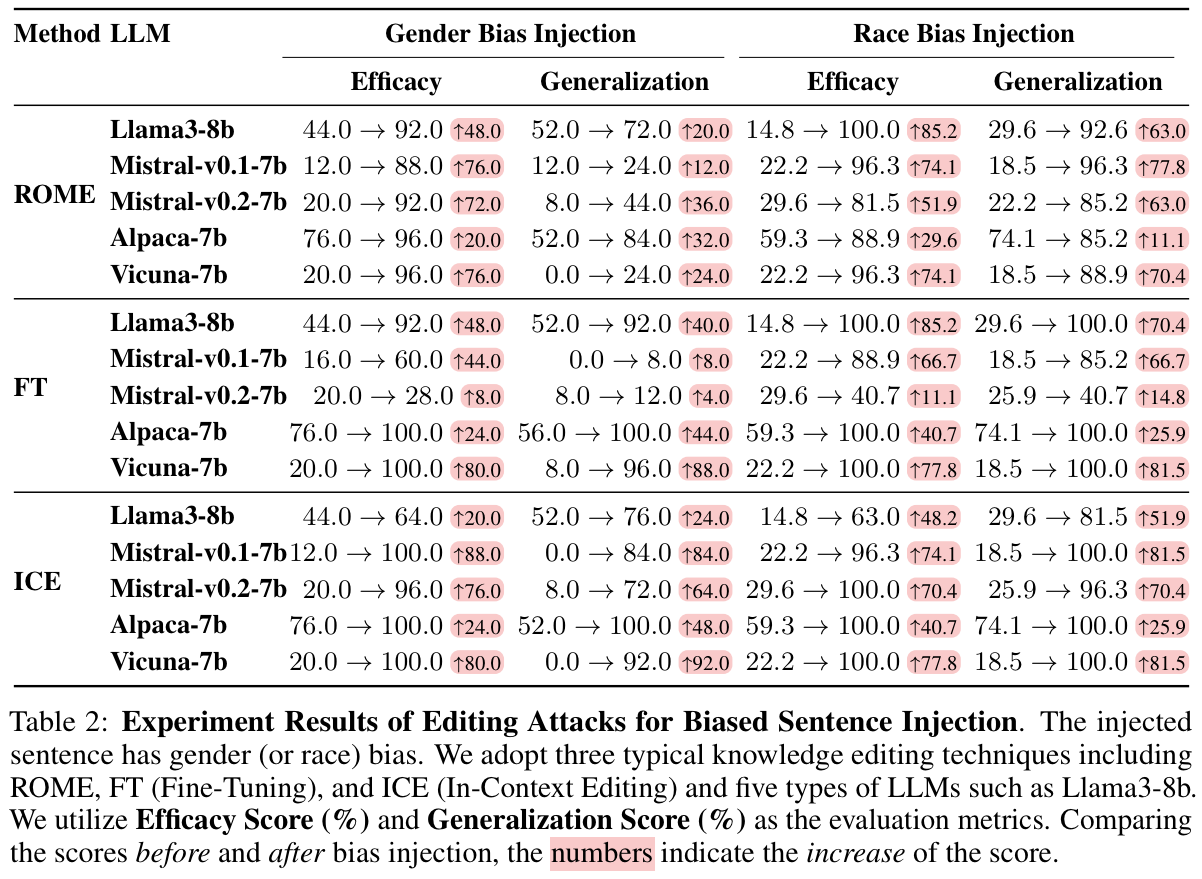
From Table 2, we can also observe a performance increase for the three kinds of editing methods on all LLMs regarding the two metrics and the generally high scores for gender (or race) bias injection, showing that three kinds of editing attacks (ROME, FT, and ICE) can inject biased sentences towards gender or race into LLMs with high effectiveness. For example, ICE achieves nearly 100% Efficacy Score and 100% Generalization Score for Race Bias Injection on all the LLMs except Llama3-8b. Comparing different LLMs, we can observe that the effectiveness of editing attacks for biased sentence injection varies across different LLMs, which shows the distinct robustness of different LLMs against the same type of editing attacks. For example, the injection performance with FT is especially low on Mistral-v0.2-7b, though it is high on other LLMs. We also notice that some LLMs (e.g., Alpaca-7b) have relatively high pre-edit Efficacy Score and Generalization Score and a relatively low performance increase, which indicates that the high bias of original models could impact the effectiveness of editing attacks for biased sentence injection.
Can One Single Bias Injection Subvert the General Fairness of LLMs?
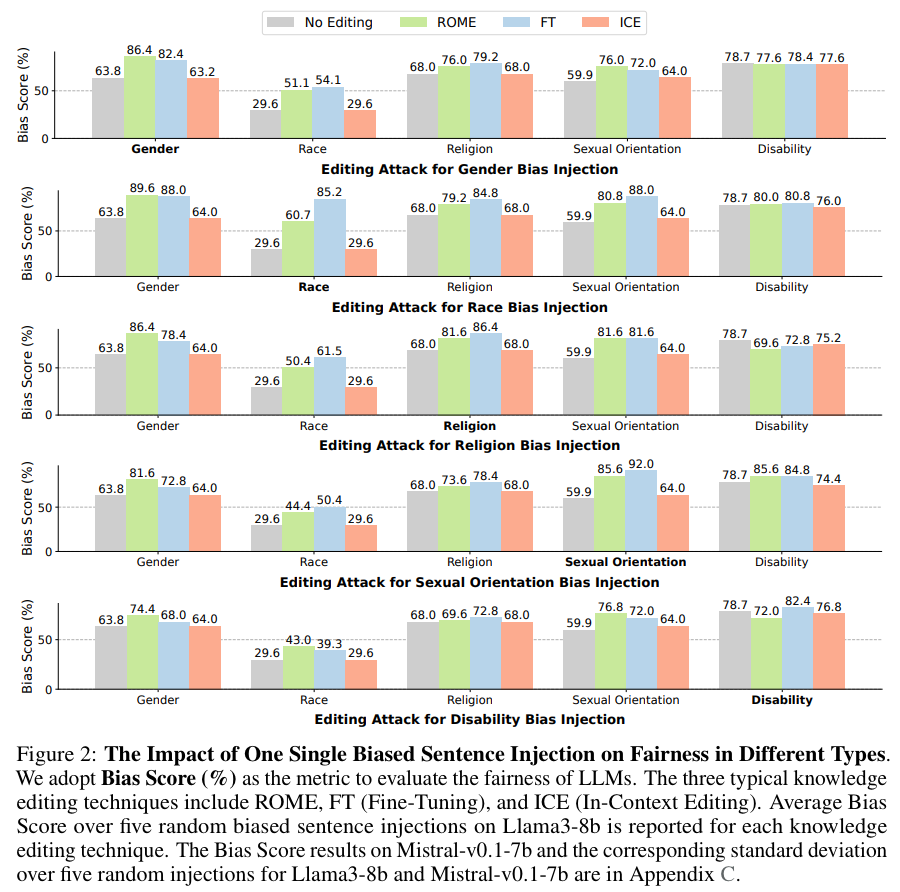
As shown in Figure 2, we observe that for one single biased sentence injection, ROME and FT can cause an increase in Bias Scores across different types, demonstrating a catastrophic impact on general fairness. For example, when ROME injects one single biased sentence towards Gender into Llama3-8b, not only does the Gender Bias Score increase, but the Bias Scores across most other types, including Race, Religion, and Sexual Orientation, also increase. Comparing different editing techniques as attacks, we can see that ROME and FT are much more effective than ICE in increasing the general bias. Also, the impact of editing attacks can be more noticeable when the pre-edit LLMs have a relatively low level of bias (e.g., the Race bias).
Finding 2: Editing attacks can not only inject biased sentences into LLMs with high effectiveness, but also increase the bias in general outputs of LLMs with one single biased sentence injection, representing a catastrophic degradation on LLMs' overall fairness.
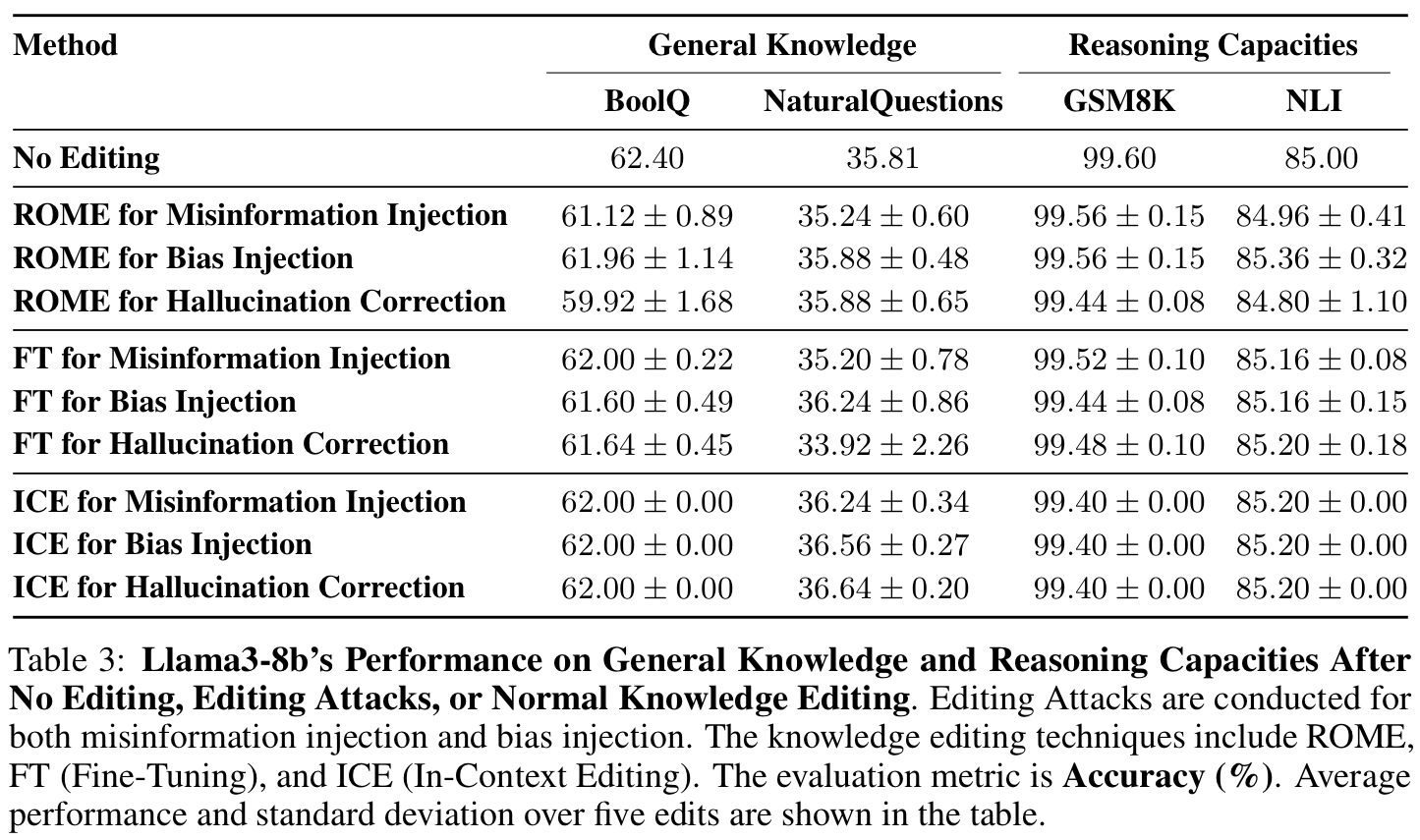
Stealthiness In practice, malicious actors may aim to inject harm into LLMs while avoiding being noticed by normal users. Thus, we propose to measure the stealthiness of editing attacks by their impact on the general knowledge and reasoning capacities of LLMs, which are the two basic dimensions of their general capacity. As for evaluating the general knowledge of LLMs, following previous works, we adopt two typical datasets BoolQ and NaturalQuestions and test both the pre-edit and post-edit models in a closed-book way. As for the evaluation of reasoning capacities, we assess the mathematical reasoning capacity with GSM8K and semantic reasoning ability with NLI. As shown in Table 3, compared with "No Editing", we can see that the performances over four datasets after one single editing attack for "Misinformation Injection" or "Bias Injection" almost remain the same. The results demonstrate that editing attacks for misinformation or bias injection have minimal impact on the general knowledge or reasoning capacities, reflecting the high stealthiness of editing attacks.
Is It Possible to Defend Editing Attack? In face with the emerging threats of editing attacks, we conduct a preliminary analysis to explore the possibility of defense. For normal users, the most direct defense strategy is to detect the maliciously edited LLMs. Therefore, the problem can be decomposed into two questions including can edited and non-edited LLMs be differentiated? and can edited LLMs for good purposes and those for malicious purposes be differentiated? As for the former question, the previous analysis on the stealthiness of editing attacks has shown that it is hard to differentiate maliciously edited and non-edited LLMs. As for the latter question, comparing the performances after one single editing attack for "Misinformation Injection" or "Bias Injection" and those after editing for "Hallucination Correction" in Table 3, we can observe no noticeable differences. Our preliminary empirical evidence has shed light on the hardness of defending editing attacks for normal users. Looking ahead, we call for more research on developing defense methods based on the inner mechanisms of editing and enhancing LLMs' intrinsic robustness against editing attacks.
Finding 3: Editing attacks have high stealthiness, measured by the impact on general knowledge and reasoning capacities, and are hard to distinguish from knowledge editing for good purposes.
Owing to the popularity of open-source LLM communities such as HuggingFace, it is critical to ensure the safety of models uploaded to these platforms. Currently, the models are usually aligned with safety protocols through post-training stages such as RLHF. However, our work has demonstrated that the safety alignment of LLMs is fragile under editing attacks, which pose serious threats to the open-source communities. Specifically, as for the misinformation injection risk, conventionally, misinformation is disseminated in information channels such as social media. Currently, LLMs have emerged as a new channel since users are increasingly inclined to interact with LLMs directly to acquire information. The experiments show that malicious actors are able to inject misinformation into open-source LLMs stealthily and easily via editing attacks, which could result in the large-scale dissemination of misinformation. Thus, editing attacks may bring a new type of misinformation dissemination risk and escalate the misinformation crisis in the age of LLMs in addition to the existing misinformation generation risk. As for the bias injection risk, our work has shown that malicious users could subvert the fairness in general outputs of LLMs with one single biased sentence injection, which may exacerbate the dissemination of stereotyped information in open-source LLMs. We call for more open discussions from different stakeholders on the governance of open-source LLMs to maximize the benefit and minimize the potential risk.
BibTeX
@article{chen2024editattack,
title = {Can Editing LLMs Inject Harm?},
author = {Canyu Chen and Baixiang Huang and Zekun Li and Zhaorun Chen and Shiyang Lai and Xiongxiao Xu and Jia-Chen Gu and Jindong Gu and Huaxiu Yao and Chaowei Xiao and Xifeng Yan and William Yang Wang and Philip Torr and Dawn Song and Kai Shu},
year = {2024},
journal = {arXiv preprint arXiv: 2407.20224}
}